The problem
Model quality is going up with new updates every now and then.
For instance, GPT 5.2 Codex just became generally available for use across tools like in Copilot/Cursor, etc.
However, if we look at pricing pages for most of these companies that provide access to the models, we can see that cost per token goes up relatively with new advancements.
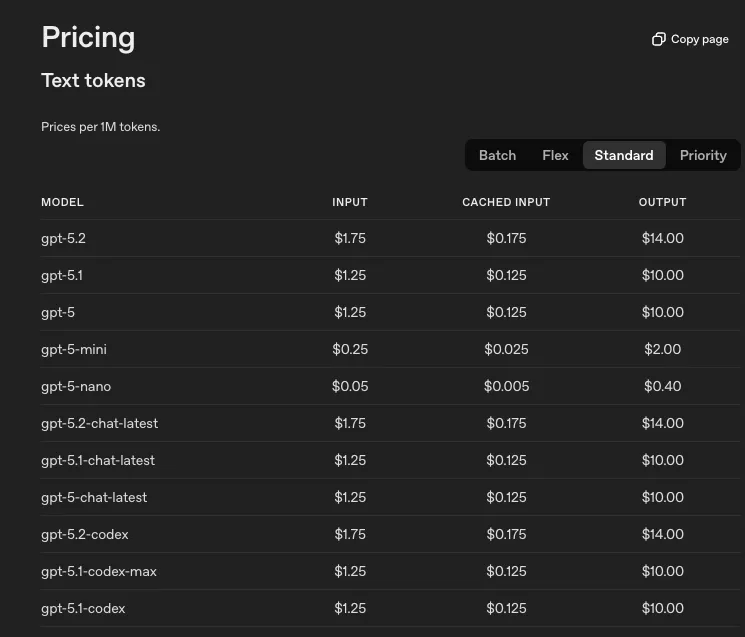
These newer models also tend to be slower than their smaller counterparts.
NOTE: Current top models from OpenAI, Anthropic, and Google primarily serve inferences using internal quantization for efficiency, often at 4-bit or lower precision, though exact details for proprietary API versions remain undisclosed.
Now this curve is improving, but the price and latency trade-off is still the gating factor on real-world deployments.
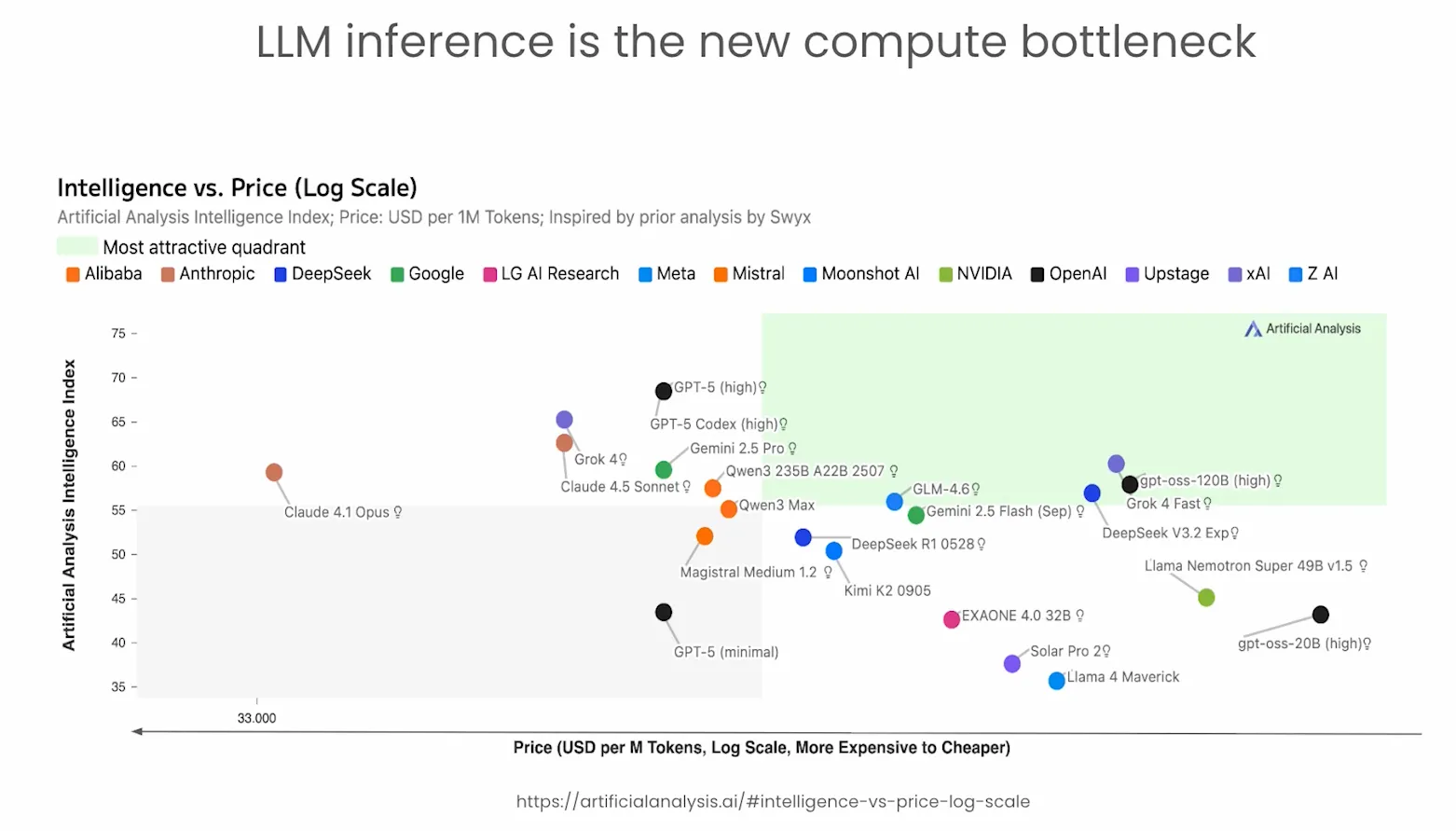
Data plumbing is no longer the largest unit cost; it’s actually inference.
Organizations are building RAG systems that ground an LLM’s response with relevant and factual data, reduce hallucinations by inserting relevant info into the LLM context, and provide up-to-date data at runtime that the LLM has never seen before.
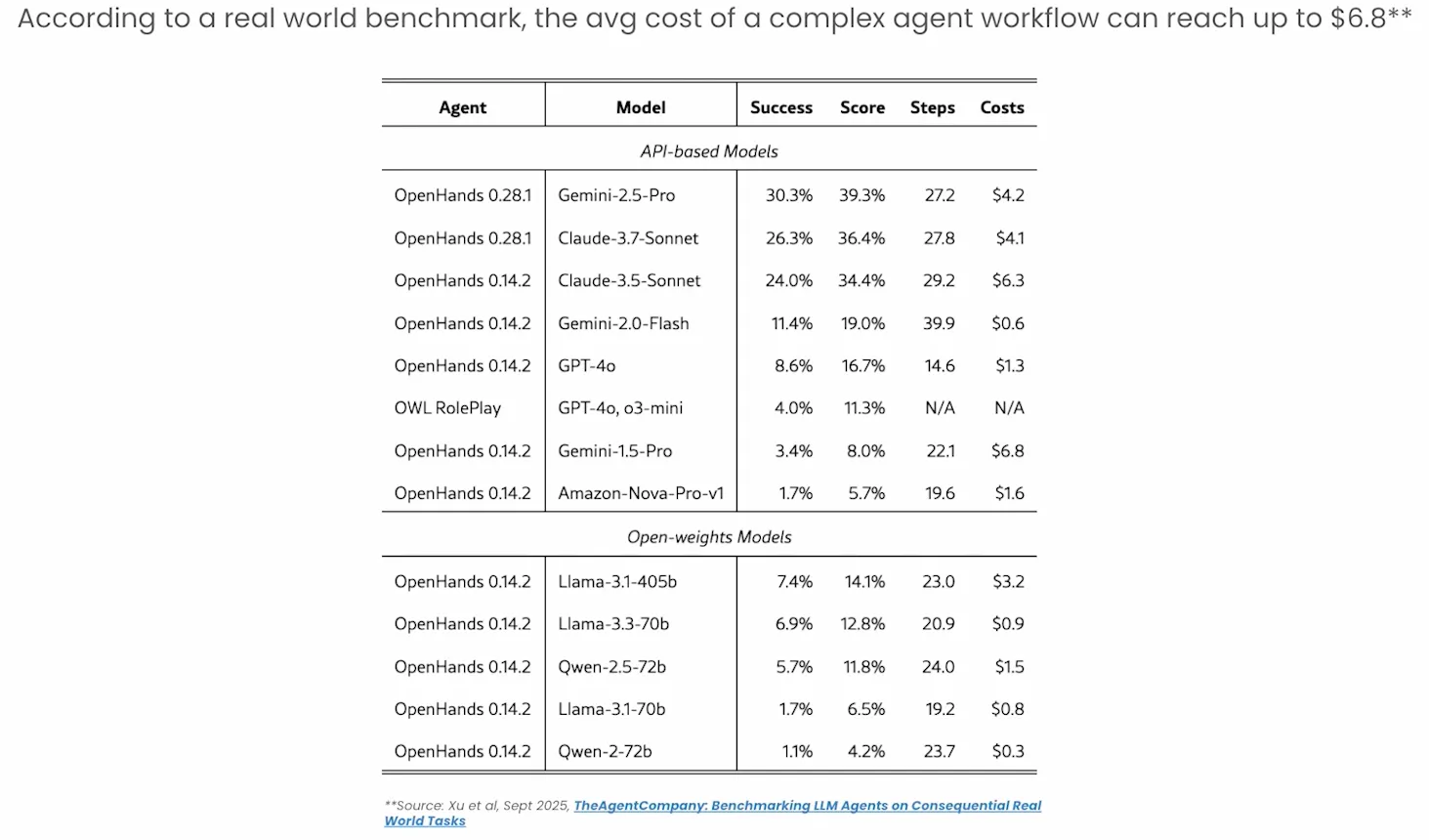
AI agents, however, are token-hungry. By nature, they extract, plan, act, reflect, and iterate.
Agents actually use many LLM calls, they consume more tokens, add additional latency. Prompts grow in length over time.
Example Scenario
Customer support agent accelerates mean time to resolution (MTTR) of open customer inquiries.
- slow agent negatively impacts customer UX
- customer support agents generate piles of FAQs
- redundant agentic RAG operations drive up infra costs $$$
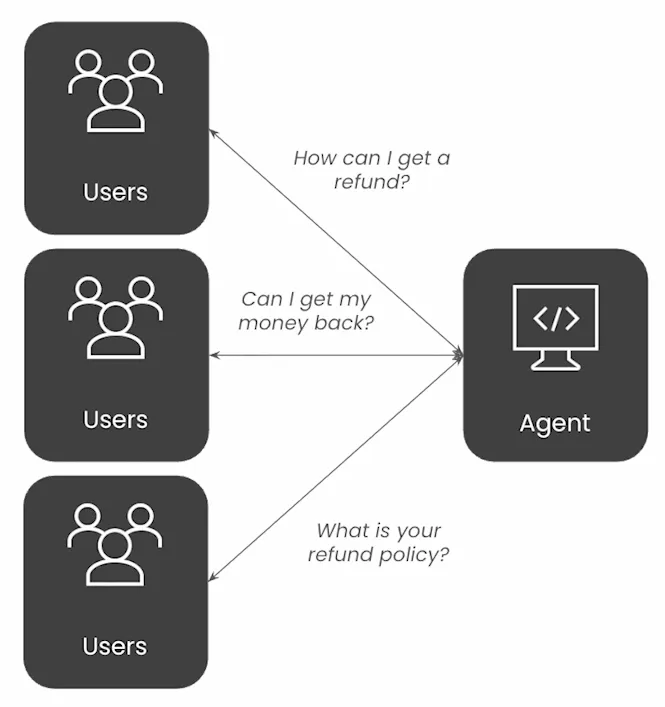
Just how many times are you going to run inference for resolution to one particular ask that is “asked” in various iterations by the user.
Enter semantic caching
Now we know that caching is the attempt to reuse existing data so we don’t have to make some kind of expensive transaction or a call to re-fetch the same data.
However, naive (exact match) caching fails for natural language.
If we rely on matching exact string data, as we do in traditional caching, the phrases users use, aka “different tokens”, would need to be exactly the same to get a cache hit.
This indexes on precision, but results in poor recall and low cache hit rates in the context of natural language, used for LLMs.
With semantic caching, we are now searching over vectorized text with optional re-ranking. This results in a higher recall and cache hit rates. However, we do have a higher risk of false positives, aka cache hits on the incorrect thing.
Vector search is the backbone of semantic caching
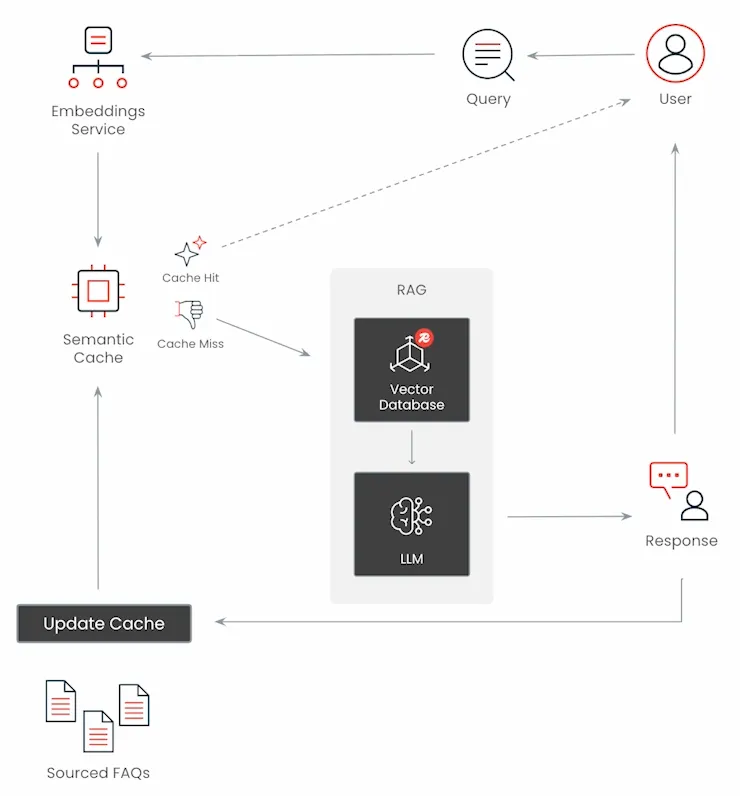
Challenges with semantic caching
- cache effectiveness
- accuracy: are we serving the correct results from the cache?
- performance: are we hitting the cache often enough? Can we serve at scale without impacting roundtrip latency?
- updatability: can we refresh, invalidate, or warm the semantic cache as data evolves over time?
- observability: can we observe and measure cache hit-rate, latency, cost savings, and cache quality?
In this post, we will look at 4 key metrics to measure the effectiveness of the cache hit rate:
- frequency — given a distance threshold, what’s the frequency of the hit rate? (primarily influences cost savings)
- precision — quality of hits (reliability)
- recall — coverage (how many possible correct results)
- F1 Score — balance between precision and recall (single measure of overall cache effectiveness)
Improving semantic caching accuracy and performance
To improve precision, we need to:
-
Optimize Precision and Recall
- adjust and tune distance threshold
- use some type of cross-encoder model (reranker) which re-ranks retrieved results, or
- use another LLM as a reranker/validator to refine semantic search outputs
These combinations should help adjust the semantic decision boundary to balance recall/precision and reduce false positives.
-
Use fuzzy matching BEFORE invoking the embeddings associated with the cache to handle typos and exact matches, saving compute.
-
Leverage context and filters for different types of context and data types (domain specific), like specific code, artifacts, etc. basically things that bypass typical caching mechanisms.
Example case study: Walmart
Walmart released a paper describing their attempt at building a production-ready semantic caching system called the “waLLMartCache”.
This is basically a distributed cache (redis) + decision engine + pre-loaded FAQs, which yielded the highest overall accuracy at ~89.6%.
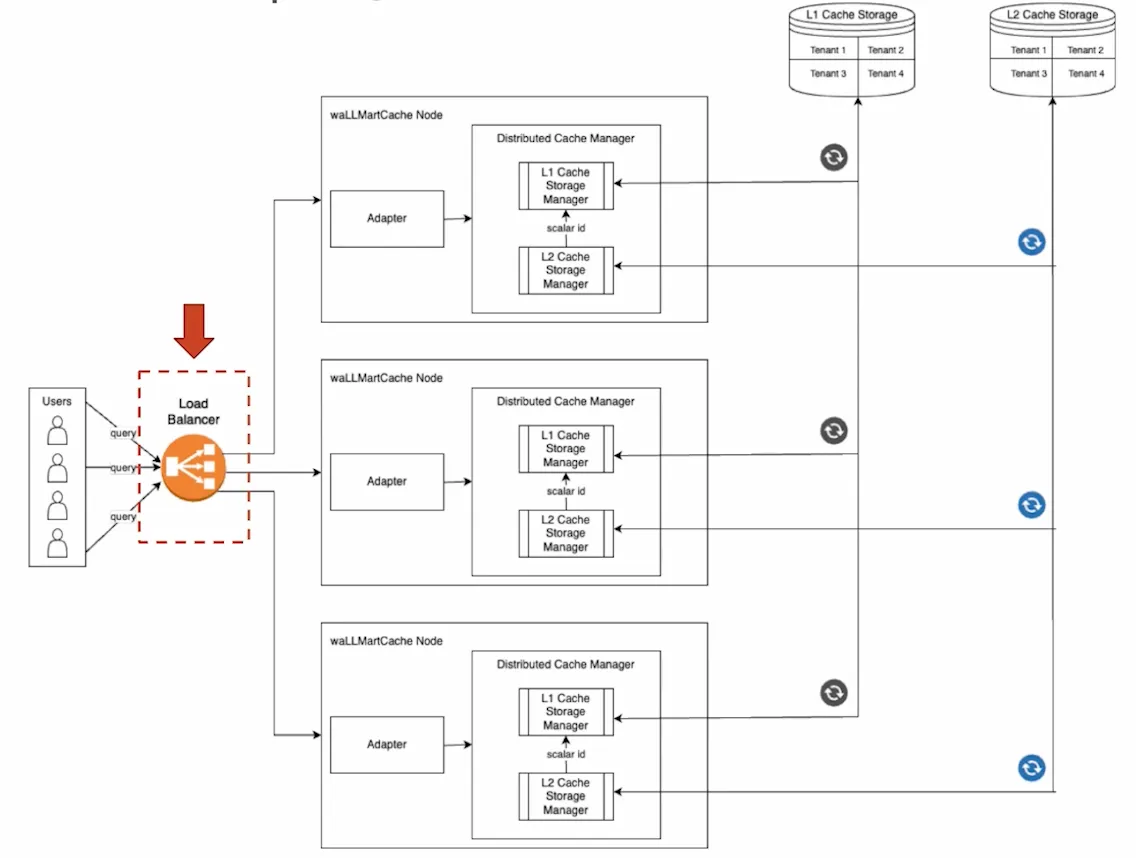
Architecture
The design has a load balancer across multiple nodes. This allows them to grow the system horizontally quite easily, and add additional nodes of compute, and the cache can scale up in terms of number of operations it can serve.
Secondly, they added a dual-tier storage for the cache, meaning there’s both an L1 and L2 layer of storage, where L1 is the simple vector DB (retrieval) based on semantic search. And L2 is a simple in memory DB like Redis for lookups given the IDs that come from the L1 cache, find metadata in L2.
Lastly is multi-tenancy. Multiple teams use the same storage infrastructure, so they can serve multiple tenants out of the same cache store.
Decision engine
Next, Walmart decided to add a decision engine to improve cache precision beyond the semantic search.
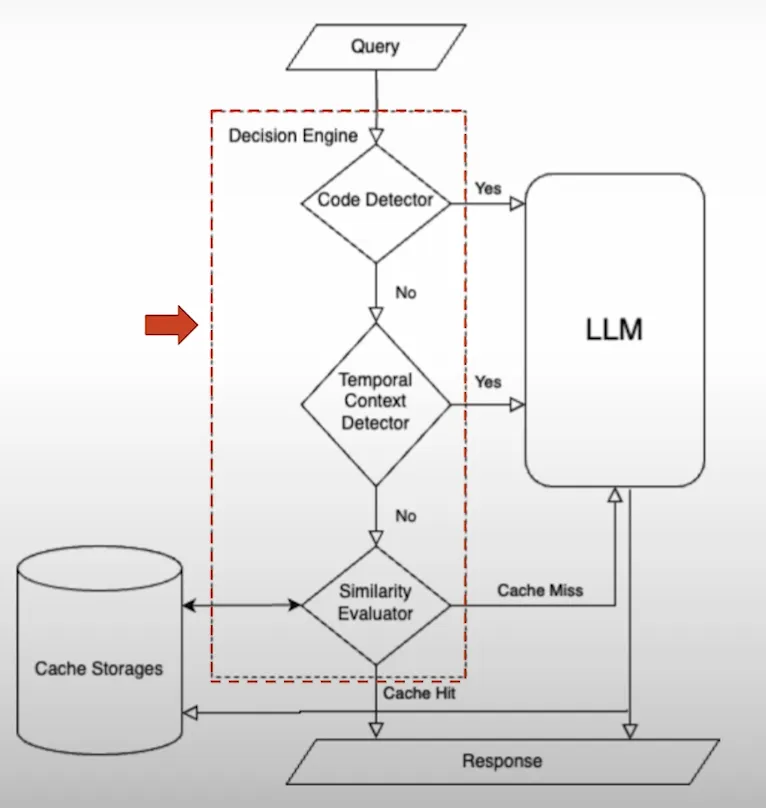
In their specific case, this decision engine was mainly to handle:
- Code detection, and
- Temporal context detection
In any case, if a user query comes in that involves code or time-sensitive information, it goes directly to the LLM/RAG based workflow, and avoid cache operations altogether.
These are both done BEFORE semantic search happens, of course.
Simple semantic search example over FAQs
Load the FAQ Dataset
import pandas as pd
import numpy as np
import time
from cache.faq_data_container import FAQDataContainer
faq_data = FAQDataContainer()
faq_df = faq_data.faq_df
test_df = faq_data.test_dfLoaded 8 FAQ entries.
Loaded 80 test queries.faq_df.head().style| id | question | answer | |
|---|---|---|---|
| 0 | How do I get a refund? | To request a refund, visit your orders page and select Request Refund. Refunds are processed within 3-5 business days. | |
| 1 | Can I reset my password? | Click Forgot Password on the login page and follow the email instructions. Check your spam folder if you don’t see the email. | |
| 2 | Where is my order? | Use the tracking link sent to your email after shipping. Orders typically arrive within 2-7 business days depending on your location. | |
| 3 | How long is the warranty? | All electronic products include a 12-month warranty from the purchase date. Extended warranties are available for purchase. | |
| 4 | Do you ship internationally? | Yes, we ship to over 50 countries worldwide. International shipping fees and delivery times vary by destination. |
Create Embeddings for Semantic Search
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("all-mpnet-base-v2")
faq_embeddings = encoder.encode(faq_df["question"].tolist())
print(f"Sample (first 10 dimensions): {faq_embeddings[0][:10]}")Sample (first 10 dimensions): [ 0.02746389 0.04248327 -0.02679515 0.03786725 -0.03876128 -0.00109464
-0.01158364 0.0307029 -0.00653776 -0.01955772]Implement basic cosine similarity semantic search
def cosine_dist(a: np.array, b: np.array):
"""Compute cosine distance between two sets of vectors."""
a_norm = np.linalg.norm(a, axis=1)
b_norm = np.linalg.norm(b) if b.ndim == 1 else np.linalg.norm(b, axis=1)
sim = np.dot(a, b) / (a_norm * b_norm)
return 1 - sim
def semantic_search(query: str) -> tuple:
"""Find the most similar FAQ question to the query."""
query_embedding = encoder.encode([query])[0]
distances = cosine_dist(faq_embeddings, query_embedding)
# Find the most similar question (lowest distance)
best_idx = int(np.argmin(distances))
best_distance = distances[best_idx]
return best_idx, best_distanceidx, distance = semantic_search(
"How long will it take to get a refund for my order?"
)
print(f"Most similar FAQ: {faq_df.iloc[idx]['question']}")
print(f"Answer: {faq_df.iloc[idx]['answer']}")
print(f"Cosine distance: {distance:.3f}")Most similar FAQ: How do I get a refund?
Answer: To request a refund, visit your orders page and select **Request Refund**. Refunds are processed within 3-5 business days.
Cosine distance: 0.331Building a simple semantic cache
def check_cache(query: str, distance_threshold: float = 0.3):
"""
Semantic cache lookup for previously asked questions.
Returns a dictionary with answer if hit, None if miss.
"""
idx, distance = semantic_search(query)
if distance <= distance_threshold:
return {
"prompt": faq_df.iloc[idx]["question"],
"response": faq_df.iloc[idx]["answer"],
"vector_distance": float(distance),
}
return None # Cache misstest_queries = [
"Is it possible to get a refund?",
"I want my money back",
"What are your business hours?", # Should miss
]
for query in test_queries:
result = check_cache(query, distance_threshold=0.3)
if result:
print(f"✅ HIT: '{query}' -> {result['response'][:50]}...")
print(f" Distance: {result['vector_distance']:.3f}\n")
else:
print(f"❌ MISS: '{query}'\n")✅ HIT: 'Is it possible to get a refund?' -> To request a refund, visit your orders page and se...
Distance: 0.262
❌ MISS: 'I want my money back'
❌ MISS: 'What are your business hours?'Adding entries to the cache
def add_to_cache(question: str, answer: str):
"""
Add a new Q&A pair to our simple in-memory cache.
Extends both the DataFrame and embeddings matrix.
"""
global faq_df, faq_embeddings
new_row = pd.DataFrame({"question": [question], "answer": [answer]})
faq_df = pd.concat([faq_df, new_row], ignore_index=True)
# Generate embedding for the new question
new_embedding = encoder.encode([question])
# Add to embeddings matrix
faq_embeddings = np.vstack([faq_embeddings, new_embedding])
print(f"✅ Added to cache: '{question}'")print("Original cache size:", len(faq_df))
new_entries = [
(
"What are your business hours?",
"We're open Monday-Friday 9 AM to 6 PM EST. Weekend support is available for urgent issues.",
),
(
"Do you have a mobile app?",
"Yes! Our mobile app is available on both iOS and Android. Search for 'CustomerApp' in your app store.",
),
(
"How do I update my payment method?",
"Go to Account Settings > Payment Methods to add, edit, or remove payment options.",
),
]
for question, answer in new_entries:
add_to_cache(question, answer)
print(f"\nCache now has {len(faq_df)} total entries")Original cache size: 8
✅ Added to cache: 'What are your business hours?'
✅ Added to cache: 'Do you have a mobile app?'
✅ Added to cache: 'How do I update my payment method?'
Cache now has 11 total entriestest_extended_queries = [
"What time do you open?",
"Is there a phone app?",
"How can I change my payment method?",
]
for query in test_extended_queries:
result = check_cache(query, distance_threshold=0.3)
if result:
print(f"✅ HIT: '{query}' -> {result['response'][:50]}...")
print(f" Distance: {result['vector_distance']:.3f}\n")
else:
print(f"❌ MISS: '{query}'\n")✅ HIT: 'What time do you open?' -> We're open Monday-Friday 9 AM to 6 PM EST. Weekend...
Distance: 0.289
✅ HIT: 'Is there a phone app?' -> Yes! Our mobile app is available on both iOS and A...
Distance: 0.265
✅ HIT: 'How can I change my payment method?' -> Go to Account Settings > Payment Methods to add, e...
Distance: 0.118Ref: Deeplearning AI
Conclusion
We went over what semantic caching is, what kind of problems it solves, and built out a very simple version. In future articles, I will be building out a personal project of mine in public involving DeepSearch that will leverage evals, semantic caching, amongst other techniques within AI/agentic optimization, to create a type of next-gen search where we are able to accuratley credit the source.
I was inspired to create this project after learning recently about the Tailwind Eng team getting laid off.
Tailwind Labs revenue collapsed about 80% from its peak, while documentation traffic dropped about 40% from early 2023 levels as most consumers of Tailwind (including myself) used AI to generate designs, instead of heading to the documentation website as one would before.
The core issue was not product adoption (which is still strong), but that AI diverted traffic away from the places where Tailwind actually monetized.
This is a highly critical time to really step back and think about how attribution would work within the AI world, the agentic world.
We’ll discuss more in future blogs. For now, ciao!